- INICIO
-
PROGRAMAS
Business
Business
IT
IT
Legaltech
Legaltech
IA Generativa
IA Generativa
- Máster en Agentes de IA e Hiperautomatización de Procesos
- Máster en Inteligencia Artificial Generativa
- Máster en Ingeniería y Desarrollo de Soluciones de IA Generativa
- Máster en Dirección Creativa y Producción Multimedia con IA
- Máster en Ingeniería de Automatización con IA Agéntica
Big Data e IA
Big Data e IA
Blockchain
Blockchain
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO



- INICIO
-
PROGRAMAS
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO
- INICIO
-
PROGRAMAS
Business
Business
IT
IT
Legaltech
Legaltech
IA Generativa
IA Generativa
- Máster en Agentes de IA e Hiperautomatización de Procesos
- Máster en Inteligencia Artificial Generativa
- Máster en Ingeniería y Desarrollo de Soluciones de IA Generativa
- Máster en Dirección Creativa y Producción Multimedia con IA
- Máster en Ingeniería de Automatización con IA Agéntica
Big Data e IA
Big Data e IA
Blockchain
Blockchain
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO

-
PROGRAMAS
Solicitar información

Ollama: Qué es y Cómo funciona (Guía 2026)
Publicado el 25/08/2025
Índice de Contenidos
Si pensabas que la inteligencia artificial avanzada solo estaba al alcance de grandes servidores y laboratorios, Ollama llegó para cambiar esa percepción. Se trata de un sistema que ejecuta modelos de lenguaje directamente en tu computadora, democratizando el acceso a herramientas sofisticadas y garantizando privacidad y control absoluto.
Al usarla, podrás descargar, configurar y personalizar modelos sin depender de servicios externos. Es fantástico, ¿no crees? Queremos que la conozcas a fondo y por eso es hora de empezar el recorrido por nuestra guía. ¡Vamos allá!
¿Qué es Ollama y para qué sirve?
Al hablar de Ollama, hablamos de una plataforma con la que es posible ejecutar modelos de inteligencia artificial, especialmente modelos de lenguaje, de manera local en tu computadora sin depender de la nube. Está diseñada para que los desarrolladores, investigadores y usuarios en general puedan descargar, gestionar y correr modelos de forma sencilla, similar a cómo se manejan los contenedores en Docker.
Sirve para probar, personalizar e integrar modelos en aplicaciones sin comprometer la privacidad de los datos, ya que todo el procesamiento se realiza en el propio equipo. Además, simplifica la experimentación con distintos modelos de IA y se despliega en entornos de desarrollo o producción flexible y seguramente.

Ventajas de su uso
Antes de sumergirte en cómo usar Ollama, es preciso que comprendas cómo la app ha captado tanta atención en el mundo de la IA. Y es que no solo ejecuta modelos de lenguaje, sino que tiene beneficios que hacen que trabajar con esta tecnología sea eficiente, seguro y creativo. Sus ventajas destacadas son:
Privacidad y control total de los datos
Al ejecutar modelos en tu propia computadora, Ollama asegura que tus datos nunca salgan de tu equipo. Esto es crucial para quienes trabajan con información delicada, proyectos confidenciales o simplemente desean mantener la privacidad.
A diferencia de servicios en la nube, aquí el control es completamente tuyo: nadie más puede acceder a tus prompts ni resultados, generando confianza y seguridad en el manejo de la información.
Acceso sin dependencia de Internet
El sistema da la opción de trabajar offline, así que puedes ejecutar modelos de IA sin necesidad de conexión a la nube. Este aspecto es preciso en lugares con internet limitado o inestable, reduce la latencia y acelera la interacción con los modelos para que la experiencia sea más fluida y confiable.
Flexibilidad y personalización de modelos
Con Ollama, puedes descargar varios modelos y ajustar parámetros según tus necesidades. Desde la temperatura de los prompts hasta la creación de Modelfiles personalizados, cada usuario puede adaptar el comportamiento del modelo a tareas específicas. Esa flexibilidad admite experimentar, desarrollar proyectos a medida y obtener resultados más precisos y útiles.
Eficiencia y optimización local
Al ejecutarse en tu propio equipo, aprovecha los recursos disponibles, como CPU y GPU, evitando cuellos de botella de servidores externos. Eso mejora el rendimiento y gestiona múltiples tareas o modelos simultáneamente, optimizando el tiempo y la capacidad de procesamiento de manera efectiva.
Te puede interesar: ejemplos de inteligencia artificial.
Características y principales funcionalidades
Antes de empezar a la herramienta, es indispensable que conozcas qué lo hace especial frente a otras de inteligencia artificial. Sus características y funcionalidades no solo facilitan la ejecución de modelos de lenguaje localmente, sino que potencian la creatividad, la productividad y la seguridad del usuario.
Ejecuta modelos de lenguaje localmente
Con la aplicación descargas y ejecutas modelos de inteligencia artificial directamente en tu computadora, eliminando la dependencia de servidores en la nube que, a su vez, disminuye la latencia, asegura mayor privacidad y te da control total sobre cómo se procesan los datos y las interacciones con la IA.
Compatibilidad con múltiples modelos
La plataforma soporta distintos modelos de lenguaje para cambiar entre ellos según la necesidad de cada proyecto. Ya sea para generación de texto, análisis de datos o asistencia creativa, te da la flexibilidad de escoger el modelo más adecuado sin restricciones externas.
Interfaz de línea de comandos y REST API
Ollama tiene una terminal intuitiva para ejecutar comandos, así como una API REST local que acepta integrar los modelos con otras aplicaciones o servicios. De ese modo, es más fácil automatizar tareas, desarrollar prototipos y experimentar sin depender de entornos complejos o costosos.
Personalización mediante Modelfiles
Puedes crear Modelfiles para ajustar parámetros de los modelos, como la temperatura, el comportamiento del asistente o el estilo de respuesta. Esa funcionalidad hace que cada proyecto tenga un modelo adaptado a sus necesidades para obtener resultados más precisos y coherentes.
Soporte para IA multimodal
Algunos modelos en Ollama trabajan con texto, imágenes y otros formatos, ampliando el rango de aplicaciones posibles. Eso abre oportunidades para tareas de creatividad, diseño, análisis visual y generación de contenido más completo e interactivo.
¿Cómo funciona?
Exactamente, funciona a través de un sistema que descarga y ejecuta modelos de lenguaje en tu computadora mediante un motor optimizado para aprovechar los recursos locales, como la CPU y, cuando es posible, la GPU. Una vez instalado, inicia modelos mediante simples comandos en la terminal, gestionando su carga y ejecución de manera similar a cómo Docker maneja contenedores.
Como usuario, podrás decidir qué modelo usar, configurarlo con parámetros personalizados y conectarlo a sus aplicaciones mediante APIs locales para asegurar rapidez y privacidad al no depender de servidores externos.

Comparativa: Ollama vs LM Studio
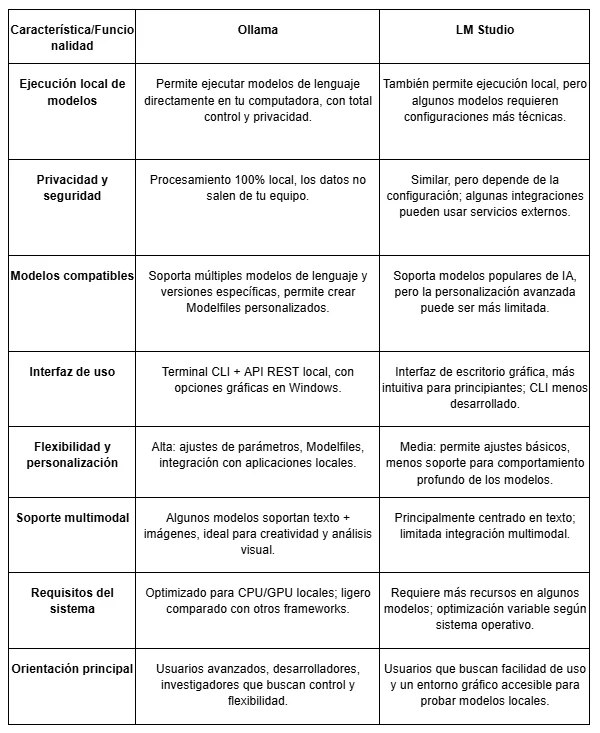
Modelos de Ollama y cómo ejecutarlos
Ya tienes varios conceptos en mente, pero ahora queremos entrar en los modelos de Ollama y en cómo ponerlos en marcha. ¿Listo? ¡Aquí vamos!
1. Llama 3.2 (Meta)
Modelo de lenguaje de alto rendimiento, adecuado para tareas generales de procesamiento de texto. Instrucciones:
Descargar el modelo:
ollama pull llama3.2
1.
Ejecutar el modelo:
ollama run llama3.2
2.
2. Gemma 2B (Google DeepMind)
Modelo ligero con 2.000 millones de parámetros, ideal para tareas rápidas y eficientes. Instrucciones:
Descargar el modelo:
ollama pull gemma:2b
1.
Ejecutar el modelo:
ollama run gemma:2b
2.
3. Mistral 7B (Mistral AI)
Modelo con 7.000 millones de parámetros, diseñado para ofrecer un equilibrio entre rendimiento y eficiencia. Instrucciones:
Descargar el modelo:
ollama pull mistral:7b
1.
Ejecutar el modelo:
ollama run mistral:7b
2.
4. Phi-4 Mini (Microsoft)
Modelo compacto y eficiente, adecuado para dispositivos con recursos limitados. Instrucciones:
Descargar el modelo:
ollama pull phi4-mini
1.
Ejecutar el modelo:
ollama run phi4-mini
2.
5. Llava (Multimodal)
Modelo que admite entradas multimodales, permitiendo procesar texto e imágenes. Instrucciones:
Descargar el modelo:
ollama pull llava
1.
Ejecutar el modelo con una imagen:
ollama run llava "ruta/a/tu/imagen.png"
2.
¿Cómo puedo instalar y usar Ollama?
Para instalar Ollama debes ir a su sitio oficial o repositorio de GitHub, donde encontrarás versiones compatibles con macOS, Windows y Linux; en sistemas Linux (como Ubuntu), suele bastar ejecutar el comando curl -fsSL https://ollama.com/install.sh | sh en una terminal KDnuggets.
Una vez instalado, puedes descargar modelos de lenguaje utilizando ollama pull <modelo> (por ejemplo, ollama pull llama3.2), y luego iniciar la interacción con el modelo mediante ollama run <modelo>.
Ollama también ofrece una interfaz REST local (escuchará por defecto en el puerto 11434) para interactuar con los modelos mediante llamadas HTTP como curl o herramientas como Postman. Para personalizar comportamientos de los modelos, se utilizan archivos llamados Modelfile, donde puedes ajustar parámetros como temperature o establecer mensajes del sistema, y después crear un nuevo modelo con ollama create; por ejemplo:
FROM llama3.2
PARAMETER temperature 1
SYSTEM "You are Mario..."
y luego:
ollama create mario -f Modelfile
ollama run mario
``` :contentReference[oaicite:3]{index=3}. Si prefieres evitar la terminal, hay opciones gráficas: una **aplicación oficial para Windows 11** que permite usar Ollama con drag-and-drop de archivos, ajustar el tamaño del contexto y representar prompts multimodales de forma visual :contentReference[oaicite:4]{index=4}, o interfaces de terceros como **Open WebUI** que funcionan en navegador usando una instancia Docker :contentReference[oaicite:5]{index=5}.
---
¿Te interesa que profundice en la personalización de modelos con Modelfile, en el uso de la API REST o en cómo instalar la interfaz gráfica en tu sistema?
::contentReference[oaicite:6]{index=6}
Ejemplos y casos de uso
- Asistencia en redacción y creación de contenido: sirve para generar textos creativos, resúmenes, artículos o correos electrónicos. Por ejemplo, un escritor puede usar Llama 3.2 para redactar un borrador inicial de un blog, mientras que un profesional de marketing puede crear campañas de correo con un estilo personalizado y coherente.
- Análisis de datos y generación de reportes: con modelos como Gemma 2B o Mistral 7B, procesa grandes volúmenes de información y crea reportes automatizados.
- Asistencia educativa y tutoría: actúa como tutor virtual, explicando conceptos complejos en lenguaje sencillo. Así, los estudiantes lo usan para practicar problemas de matemáticas, recibir explicaciones de historia o aprender nuevos idiomas con ejemplos interactivos.
- Creatividad multimodal (texto + imagen): modelos como Llava permiten combinar texto e imagen, generando contenido visual junto con descripciones o análisis. Es preciso para diseñadores gráficos, creadores de contenido educativo o investigadores que necesitan interpretar datos visuales de manera integrada.
- Automatización de tareas y prototipos: usando la API REST de Ollama, los desarrolladores integran los modelos en aplicaciones, automatizando respuestas de atención al cliente, chatbots inteligentes o generación de documentos.
Te puede interesar: llama 3.
Consejos y mejores prácticas para optimizar su uso
Con algunos ajustes simples y buenas prácticas, puedes mejorar la eficiencia, la precisión de los modelos y la experiencia general de uso con Ollama. Estos consejos te ayudarán como usuario novato e incluso como desarrollador avanzado:
Elegir el modelo adecuado para cada tarea
No todos los modelos son iguales. Modelos ligeros como Gemma 2B son mejores para tareas rápidas y con recursos limitados, mientras que Llama 3.2 o Mistral 7B funcionan mejor para generación de texto compleja o análisis profundo. Seleccionar el modelo correcto mejora el rendimiento y la relevancia de las respuestas.
Ajustar parámetros de los modelos
Parámetros como temperatura, máximo de tokens y estilo de respuesta influyen directamente en la creatividad y coherencia de las respuestas. Por ejemplo, una temperatura baja genera respuestas más precisas y formales, mientras que una temperatura alta produce resultados más creativos y variados.
Usar Modelfiles personalizados
Crear Modelfiles permite personalizar un modelo según tus necesidades específicas, como comportamiento del asistente, tono de las respuestas o reglas de interacción. Esto asegura que el modelo se adapte a proyectos concretos sin perder consistencia.
Mantener los modelos actualizados
Ollama recibe actualizaciones y mejoras de modelos periódicamente. Descargar la versión más reciente de un modelo garantiza mayor rendimiento, mejores resultados y acceso a nuevas funcionalidades.
Aprovechar la ejecución local y la API REST
Ejecutar modelos localmente disminuye la latencia y potencia la privacidad. Además, usar la API REST integra a Ollama en aplicaciones, automatizando tareas y optimizando flujos de trabajo.
Preguntas frecuentes (FAQs)
Antes de empezar a usar Ollama, es normal que tengas dudas sobre su instalación, modelos y funcionamiento. Por eso es que creamos esta sección de “Preguntas frecuentes” para responder las consultas más habituales.
¿Cuáles son los requisitos del sistema para Ollama?
Ollama funciona en Windows, macOS y Linux. Para un rendimiento óptimo, se recomienda contar con 8 GB de RAM mínimo, procesador moderno (CPU o GPU compatible) y espacio suficiente en disco para descargar modelos, que pueden variar entre 2 y 20 GB dependiendo del modelo.
¿Cuál es el modelo más rápido en Ollama?
Los modelos más ligeros, como Gemma 2B o Phi-4 Mini, son los más rápidos en ejecución, precisos para tareas rápidas o sistemas con recursos limitados. Modelos grandes como Llama 3.2 tienen mayor precisión, pero requieren más memoria y tiempo de procesamiento.
¿Dónde almacena Ollama los modelos?
Por defecto, guarda los modelos descargados en una carpeta local dentro del sistema. La ubicación exacta depende del sistema operativo:
- Windows: C:\Users\<usuario>\AppData\Local\Ollama\models
- macOS: /Users/<usuario>/Library/Application Support/Ollama/models
- Linux: /home/<usuario>/.ollama/models
¿Cómo puedo configurar Ollama?
- Comandos CLI: ajustes de parámetros como temperatura, tokens máximos o selección de modelo.
- Modelfiles personalizados: para crear modelos con comportamiento y estilo adaptados a tus necesidades.
- API REST: permite integraciones avanzadas en aplicaciones locales o automatización de tareas.
¿Es Ollama gratuito?
El sistema tiene una versión básica gratuita para descargar y ejecutar ciertos modelos de manera local. Para acceder a modelos más grandes o funcionalidades avanzadas, puede requerirse licencia o suscripción, dependiendo de los modelos y actualizaciones disponibles en 2026.
Domina la IA local con Ollama y transforma tu futuro con EBIS
Esta innovadora herramienta hace posible trabajar con inteligencia artificial de forma ágil y personalizada, ideal para desarrolladores, analistas y profesionales que buscan eficiencia en sus proyectos.
En EBIS Business Techschool, centro de formación en nuevas tecnologías, incluimos técnicas para aprender a gestionar herramientas como Ollama en nuestro Máster en Inteligencia Artificial Generativa y el Máster en Agentes de IA. Con un enfoque que combina teoría y práctica actualizada para que domines los usos profesionales de la IA generativa.
Al completar el programa, obtendrás una doble titulación de EBIS y la Universidad de Vitoria-Gasteiz, además de tener acceso a certificaciones internacionales como Azure AI Fundamentals (AI-900) y Harvard ManageMentor® en Liderazgo para impulsar tu perfil profesional.
Prepárate para trabajar con lo último en Inteligencia Artificial y conviértete en un experto en EBIS.
Conclusión
Terminamos diciéndote que Ollama simboliza un cambio radical en la forma de usar inteligencia artificial. Ejecutar modelos de lenguaje localmente ya no es un privilegio exclusivo de grandes corporaciones, sino una posibilidad real para cualquier usuario. Aquí te hablamos su funcionamiento, instalación y uso práctico, destacando cómo la plataforma equilibra potencia, privacidad y accesibilidad. Al dominar la app, ganarás control total sobre sus interacciones con la IA, desde la experimentación hasta la integración en proyectos personales o profesionales. Es la prueba de que la innovación tecnológica puede ser poderosa, flexible y, sobre todo, cercana a quienes la usan.
Compártelo en tus redes sociales
Másteres destacados






Centro inscrito en el Registro Estatal de Entidades de Formación en virtud de la ley 30/2015
EBIS Enterprise SL, B75630632; C. Agustín Millares, 18, 35001 Las Palmas de Gran Canaria; © 2025 EBIS Business Techschool,