- INICIO
-
PROGRAMAS
Business
Business
IT
IT
Legaltech
Legaltech
IA Generativa
IA Generativa
- Máster en Agentes de IA e Hiperautomatización de Procesos
- Máster en Inteligencia Artificial Generativa
- Máster en Ingeniería y Desarrollo de Soluciones de IA Generativa
- Máster en Dirección Creativa y Producción Multimedia con IA
- Máster en Ingeniería de Automatización con IA Agéntica
Big Data e IA
Big Data e IA
Blockchain
Blockchain
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO



- INICIO
-
PROGRAMAS
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO
- INICIO
-
PROGRAMAS
Business
Business
IT
IT
Legaltech
Legaltech
IA Generativa
IA Generativa
- Máster en Agentes de IA e Hiperautomatización de Procesos
- Máster en Inteligencia Artificial Generativa
- Máster en Ingeniería y Desarrollo de Soluciones de IA Generativa
- Máster en Dirección Creativa y Producción Multimedia con IA
- Máster en Ingeniería de Automatización con IA Agéntica
Big Data e IA
Big Data e IA
Blockchain
Blockchain
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO

-
PROGRAMAS
Solicitar información

Apache Spark: Guía Completa (2026)
Publicado el 24/11/2025
Índice de Contenidos
¿Alguna vez has pensado en un escenario donde millones de datos fluyen sin freno, y tu trabajo es convertirlos en conocimiento útil? Ahí es donde Apache Spark entra en juego: un motor que acelera análisis, predicciones y decisiones en tiempo récord. No importa si eres principiante o profesional del dato, hoy te aprenderemos desde los conceptos básicos hasta consejos prácticos, pasando por comparativas con otras herramientas y FAQs esenciales. Descubrirás cómo Spark combina potencia, flexibilidad y escalabilidad para proyectos de cualquier tamaño, y cómo puedes incorporarlo a tu flujo de trabajo sin complicaciones. ¿Listo? ¡No esperemos más!
¿Qué es Apache Spark y para qué sirve?
Apache Spark es como un motor de datos que trabaja en equipo: en lugar de procesar la información en una sola máquina, la reparte en muchas y las hace trabajar al mismo tiempo para analizar volúmenes gigantes de datos sin que todo se vuelva lento o torpe.

No se limita a “consultar” datos; puede limpiarlos, transformarlos, analizarlos en tiempo real y hasta alimentar modelos de inteligencia artificial. Lo usan empresas que necesitan obtener conclusiones rápidas a partir de millones de registros, como detectar fraudes, recomendar productos o analizar tendencias al vuelo, sin que la espera se vuelva el cuello de botella.
Ventajas
Cuando trabajas con grandes volúmenes de información, la velocidad y la flexibilidad son clave. Apache Spark no solo acelera el procesamiento, sino que transforma el análisis de datos, haciéndolo más sencillo, rápido y potente. Usarlo te dará estás fantásticas ventajas:
Procesamiento en memoria ultra rápido
Al mantener los datos directamente en memoria durante las operaciones, las tareas que normalmente tardarían minutos u horas se completan en segundos. Por eso es genial para análisis iterativos y proyectos de machine learning donde la velocidad marca la diferencia.
Soporte para múltiples lenguajes
Spark ofrece APIs para Python, Scala, Java y R para que los equipos trabajen con el lenguaje que mejor conocen, y así reducir la curva de aprendizaje y facilitar la integración con proyectos existentes.
Capacidad de análisis en tiempo real
No se limita al procesamiento por lotes: también puede manejar flujos de datos continuos. Esto permite reaccionar inmediatamente a eventos, alertas o cambios en la información, algo fundamental para aplicaciones financieras, IoT o monitoreo de sistemas.
Integración con ecosistemas existentes
Se conecta fácilmente con Hadoop, Hive, Kafka y muchas otras herramientas, para potenciar su adopción en infraestructuras ya existentes sin grandes reestructuraciones.
Escalabilidad sin complicaciones
Desde un único ordenador hasta miles de nodos en un cluster, la arquitectura logra crecer según las necesidades sin perder rendimiento ni estabilidad.
Amplias capacidades analíticas
Incluye bibliotecas integradas para machine learning, análisis de gráficos y procesamiento de datos estructurados, y eso elimina la necesidad de herramientas adicionales y centraliza todo en un solo entorno.
¿Cómo funciona?
En Spark, el proceso comienza cuando defines las operaciones que quieres realizar sobre los datos. A partir de eso, el sistema construye un plan lógico y lo traduce en un grafo de tareas (DAG), donde cada paso puede ejecutarse de forma paralela. Un componente llamado Driver se encarga de coordinar la ejecución y comunica las tareas al Cluster Manager, que distribuye los recursos disponibles entre las máquinas del clúster.
Cada máquina ejecuta su parte mediante Executors, que mantienen los datos en memoria para acelerar el procesamiento. Si alguna tarea falla, el sistema tiene la posibilidad de recalcularla gracias al historial de transformaciones, y al final devuelve o almacena el resultado final sin gestionar los detalles internos.
¿Cuál es la arquitectura de Apache Spark?
La arquitectura de datos se basa en un modelo maestro-trabajador. En el centro se encuentra el Driver Program, que ejecuta el código del usuario y genera el plan de tareas. Ese plan se distribuye a través del Cluster Manager (que puede ser YARN, Mesos, Kubernetes o el gestor propio de Spark), encargado de asignar recursos a las máquinas.
Cada una de esas máquinas ejecutoras se conoce como Worker Node, y dentro de ellas se inician los Executors, que son los procesos que realmente ejecutan las tareas y almacenan los datos en memoria durante el procesamiento.
Además, Spark se organiza en capas: en la base están los RDDs y el motor de ejecución, sobre ellos Spark SQL, MLlib, GraphX y Structured Streaming, que proveen capacidades para análisis, machine learning, grafos y procesamiento en tiempo real.
Apache Spark vs. Hadoop MapReduce
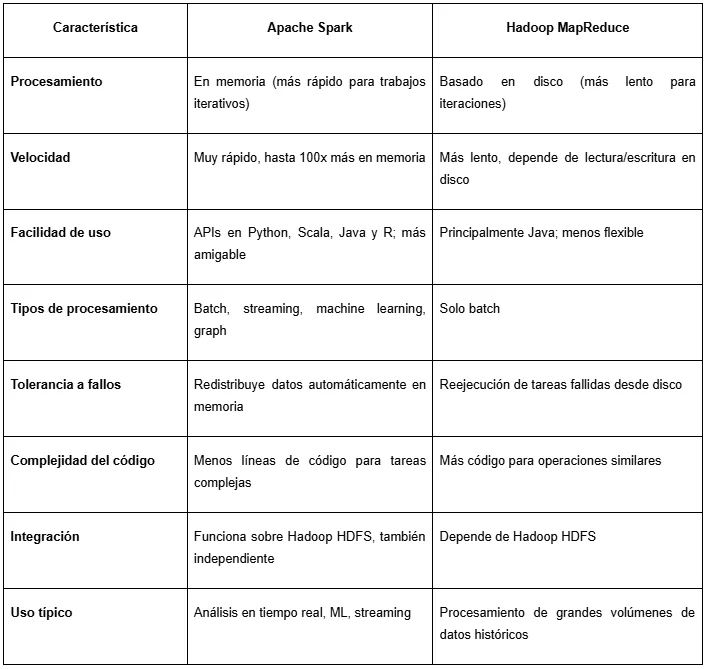
Spark vs Flink
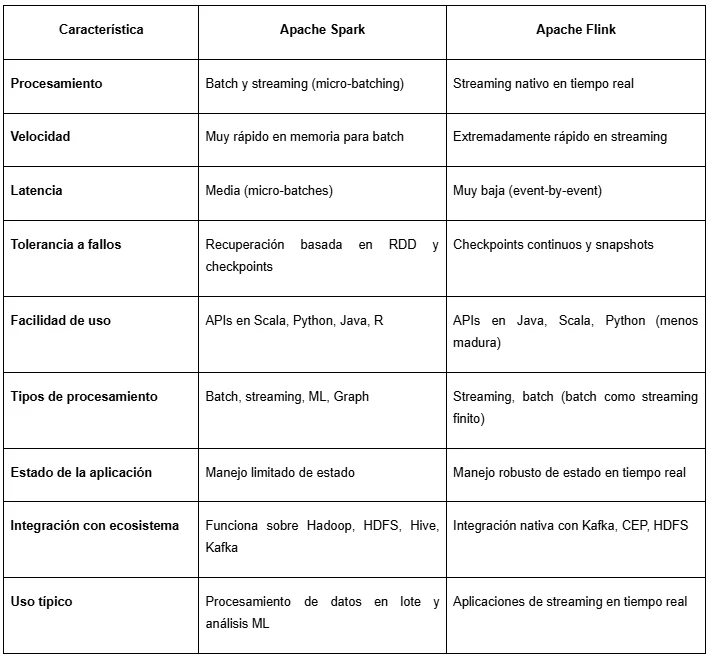
Cómo instalar y comenzar a utilizarlo (paso a paso)
- Descargar Spark: dirígete a la página oficial de Apache Spark y descarga la versión más reciente compatible con tu sistema operativo y con Hadoop si planeas integrarlo.
- Instalar Java: procura tener instalado Java 8 o superior y que la variable de entorno JAVA_HOME esté configurada.
- Configurar variables de entorno: define SPARK_HOME apuntando a la carpeta donde descomprimiste Spark y agrega SPARK_HOME/bin al PATH.
- Instalar Python (opcional): si usarás PySpark, instala Python y configura PYSPARK_PYTHON apuntando al intérprete que usarás.
- Iniciar Spark localmente: abre la terminal y ejecuta spark-shell (para Scala) o pyspark (para Python) para entrar al entorno interactivo.
- Probar con un ejemplo: ejecuta operaciones sencillas como sc.parallelize([1,2,3,4]).count() para verificar que Spark funcione correctamente.
- Configurar notebooks (opcional): si prefieres trabajar en Jupyter, instala findspark y configura tu notebook para usar Spark desde Python.
- Avanzar a cluster mode: cuando ya domines lo local, configura un cluster de Spark con master y workers para procesar datos a gran escala.
Te puede interesar: herencia en Python.
Desventajas y limitaciones
Está claro que hemos hablado de una herramienta potente que ha revolucionado el procesamiento de datos a gran escala, pero como todo en tecnología, no es perfecta. Así que lee sus desventajas antes de usarla:
Requerimientos de memoria elevados
El rendimiento de Spark depende en gran medida de la memoria RAM disponible. Al procesar grandes volúmenes de datos en memoria, si no se dispone de suficiente espacio, las tareas pueden ralentizarse o incluso fallar, obligando a ajustar configuraciones o a invertir en hardware más potente.
Complejidad en la configuración y administración
Aunque el desarrollo con Spark puede ser más simple que con MapReduce, la instalación y gestión de clusters resulta complicada. Ajustar parámetros de memoria, particionamiento y paralelismo requiere experiencia para evitar cuellos de botella o desperdicio de recursos.
Limitaciones para cargas pequeñas
Para tareas pequeñas o poco complejas, puede ser excesivo. Su overhead de inicialización y gestión de clusters hace que procesos simples tarden más que con herramientas más ligeras o scripts tradicionales.
Ejemplos y casos prácticos de Apache Spark
Imagina poder analizar terabytes de información en minutos, predecir comportamientos de clientes antes que la competencia o reaccionar en tiempo real a eventos que ocurren a tu alrededor. Como ya lo dijimos, Apache Spark hace todo esto posible. Te servirá para esto y mucho más:
Análisis de grandes volúmenes de datos
Las compañías de retail y marketing utilizan Spark para examinar enormes bases de datos de clientes y ventas. Esto identificar patrones de comportamiento, segmentar audiencias y predecir tendencias de compra sin esperar horas o días por los resultados, algo que sería inviable con métodos tradicionales. La velocidad y escalabilidad que brinda, hacen posible responder a preguntas complejas casi en tiempo real.
Procesamiento de streaming en tiempo real
En sectores como telecomunicaciones o fintech, es fundamental analizar eventos a medida que ocurren. Con Spark Streaming, los datos de sensores, transacciones o redes sociales se procesan al instante, simplificando alertas automáticas, detección de fraudes o recomendaciones personalizadas al usuario en el momento justo.
Machine learning y predicciones avanzadas
Gracias a MLlib, la biblioteca de machine learning de Spark, los equipos de ciencia de datos pueden entrenar modelos predictivos sobre conjuntos de datos gigantescos sin dividir el trabajo en múltiples plataformas. Eso se traduce en predicciones más precisas para desde sistemas de recomendación hasta optimización logística.
Integración y procesamiento de datos heterogéneos
Spark se adapta a distintos formatos y fuentes: HDFS, bases SQL y NoSQL, archivos JSON o CSV, para combinar información de diferentes sistemas para generar reportes unificados, análisis de tendencias o dashboards interactivos, todo desde un único entorno, ahorrando tiempo y esfuerzo en la integración de datos.
Mejores prácticas y consejos de uso
En este punto ya no hay dudas de que la herramienta puede transformar la manera en que manejas y analizas datos. No se trata únicamente de velocidad, sino de cómo estructurar tus procesos y aprovechar sus capacidades sin complicarte. Así que esos consejos te ayudarán a usarlo debidamente:
Optimiza el uso de memoria
Evita que tus procesos se ralenticen ajustando la cantidad de memoria asignada a cada nodo y a los ejecutores. Controlar la memoria te deja ejecutar tareas más grandes en paralelo y prevenir errores por falta de recursos, sobre todo cuando trabajas con grandes volúmenes de datos.
Divide y vencerás: particionamiento inteligente
Organizar tus datos en particiones adecuadas facilita la distribución del trabajo entre nodos. Particiones bien diseñadas mejoran la velocidad de procesamiento y reducen la necesidad de mover grandes cantidades de información de un nodo a otro.
Aprovecha las APIs de alto nivel
Las librerías integradas para machine learning, gráficos y streaming permiten construir soluciones complejas sin reinventar la rueda. Usar estas herramientas simplifica tu código y acelera la implementación de proyectos sofisticados.
Monitorea y ajusta continuamente
El seguimiento de métricas y registros de ejecución te ayuda a identificar cuellos de botella. Ajustar parámetros como número de ejecutores, tamaño de particiones y memoria disponible hace la diferencia en eficiencia y estabilidad.
Integra con otras herramientas
Conectar Spark con bases de datos, sistemas de mensajería o Hadoop HDFS amplía sus posibilidades. La integración correcta asegura flujos de datos más fluidos y menos problemas al trabajar con entornos heterogéneos.
Preguntas frecuentes (FAQs)
Si ahora quieres saber cómo aprovechar datos masivos sin perder velocidad ni eficiencia, estas preguntas te ayudarán a despejar dudas clave. Desde costos y lenguajes de programación hasta adopción en empresas y compatibilidad con la nube, aquí encontrarás respuestas directas que facilitan comprender por qué Spark sigue siendo una herramienta central en el mundo del big data. ¡Comencemos!
¿Tiene Apache Spark algún coste?
Apache Spark es de código abierto, por lo que usarlo de forma básica no implica coste alguno. No obstante, si decides ejecutarlo en plataformas en la nube administradas o integrarlo con servicios empresariales, podrían aplicarse tarifas según la infraestructura o el servicio que elijas.
¿Qué empresas utilizan Apache Spark?
Compañías como Netflix, Uber, Amazon y eBay lo emplean para análisis de grandes volúmenes de datos, recomendaciones personalizadas y procesamiento en tiempo real. También muchas startups y empresas medianas lo utilizan para proyectos de big data debido a su velocidad y flexibilidad.
¿Qué lenguaje es mejor usar con Spark: Python o Scala?
Python, mediante PySpark, permite desarrollar rápidamente y es ideal para análisis de datos y machine learning. Scala tiene un rendimiento más cercano al núcleo de Spark y acceso a todas sus funcionalidades. La elección depende de si priorizas rapidez de desarrollo o eficiencia máxima.
¿Merece la pena aprender Apache Spark en 2026?
Sí. Spark sigue siendo relevante gracias al aumento constante de datos, análisis en tiempo real y machine learning. Usarlo te abre oportunidades en ingeniería de datos, ciencia de datos y proyectos de big data, convirtiéndose en una habilidad muy valorada en el mercado laboral.
¿Spark funciona en la nube?
Sí, puede ejecutarse en servicios como AWS, Google Cloud o Azure, ya sea en clusters propios o mediante soluciones administradas como Dataproc, EMR o Synapse. Esto facilita escalar proyectos sin necesidad de infraestructura física y aprovechar el procesamiento distribuido al máximo.
Domina el procesamiento de datos a gran escala con Apache Spark junto a EBIS
En los últimos años, Apache Spark se ha convertido en una de las herramientas más potentes para procesar información masiva gracias a su capacidad de operar en memoria, ejecutar cálculos distribuidos y adaptarse tanto a análisis batch como a procesamiento en tiempo real.
En EBIS Business Techschool, integramos el aprendizaje de Apache Spark dentro de un enfoque formativo orientado al desarrollo profesional. En el Máster en Data Science e Inteligencia Artificial, aprenderás a trabajar con Spark desde cero: creación de DataFrames, optimización de consultas distribuidas, uso de Spark SQL y aplicación de modelos de Machine Learning con Spark MLlib, todo mediante prácticas guiadas y proyectos reales.
Nuestro programa se distingue por ofrecer formación práctica desde el primer módulo, mentores especializados en Big Data y Data Engineering, implementación de soluciones reales en entornos empresariales y certificaciones reconocidas internacionalmente, entre ellas:
- Microsoft Azure AI Fundamentals
- Harvard ManageMentor® – Leadership
- Doble titulación junto a la Universidad de Vitoria-Gasteiz
Si buscas destacar en áreas como análisis avanzado de datos, ingeniería de datos o desarrollo de sistemas inteligentes, dominar Apache Spark es una ventaja decisiva. ¡Construye el futuro de tu carrera con EBIS y Spark como tus aliados!
Conclusión
Dominar Apache Spark no es nada más aprender una tecnología, sino cambiar la forma de trabajar con datos. Su potencia en memoria y capacidad de procesamiento distribuido permiten analizar información más rápido y con menos complicaciones. Conocer su arquitectura, instalarlo correctamente y aplicar buenas prácticas marca la diferencia entre proyectos eficientes y cuellos de botella constantes. Igualmente, la experiencia con Spark abre oportunidades en ciencia de datos, machine learning y proyectos en la nube.
Compártelo en tus redes sociales
Másteres destacados






Centro inscrito en el Registro Estatal de Entidades de Formación en virtud de la ley 30/2015
EBIS Enterprise SL, B75630632; C. Agustín Millares, 18, 35001 Las Palmas de Gran Canaria; © 2025 EBIS Business Techschool,