- INICIO
-
PROGRAMAS
Business
Business
IT
IT
Legaltech
Legaltech
IA Generativa
IA Generativa
- Máster en Agentes de IA e Hiperautomatización de Procesos
- Máster en Inteligencia Artificial Generativa
- Máster en Ingeniería y Desarrollo de Soluciones de IA Generativa
- Máster en Dirección Creativa y Producción Multimedia con IA
- Máster en Ingeniería de Automatización con IA Agéntica
Big Data e IA
Big Data e IA
Blockchain
Blockchain
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO



- INICIO
-
PROGRAMAS
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO
- INICIO
-
PROGRAMAS
Business
Business
IT
IT
Legaltech
Legaltech
IA Generativa
IA Generativa
- Máster en Agentes de IA e Hiperautomatización de Procesos
- Máster en Inteligencia Artificial Generativa
- Máster en Ingeniería y Desarrollo de Soluciones de IA Generativa
- Máster en Dirección Creativa y Producción Multimedia con IA
- Máster en Ingeniería de Automatización con IA Agéntica
Big Data e IA
Big Data e IA
Blockchain
Blockchain
- DOCENTES
-
ALUMNOS
- ECOSISTEMA EBIS
- EMPRESAS
- CONTACTO

-
PROGRAMAS
Solicitar información

MLflow: Todo lo que Necesitas Saber (2026)
Publicado el 30/09/2025
Índice de Contenidos
Cada vez que disfrutas una recomendación en Netflix, un traductor automático o una app inteligente, detrás hay incontables modelos que fueron entrenados, probados y desplegados con precisión quirúrgica. Sin embargo, la mayoría de esas herramientas no serían posibles sin plataformas que gestionan ese ciclo de vida.
MLflow, nacido en Databricks, es una de esas revoluciones silenciosas: trabaja en segundo plano, asegurando que la ciencia de datos no sea improvisación, sino un proceso organizado y reproducible. Su presencia es casi obligatoria para cualquier equipo que quiera sobrevivir en la carrera de la inteligencia artificial aplicada.
¿Qué es MLflow?
MLflow es una plataforma de código abierto diseñada para gestionar todo el ciclo de vida del machine learning, desde los experimentos iniciales hasta el despliegue en producción. Su objetivo principal es ayudar a los equipos de ciencia de datos y aprendizaje automático a organizar y dar seguimiento a sus modelos de manera más eficiente.
Ofrece herramientas para registrar experimentos (guardando métricas, parámetros y resultados), empaquetar modelos en formatos reutilizables y desplegarlos en distintos entornos sin depender de una infraestructura específica. Además, es flexible porque se integra con varios lenguajes, frameworks y servicios en la nube, lo que facilita su adopción en proyectos variados.

Te puede interesar: arquitectura de datos.
Origen y evolución
El sistema nació en 2018 como un proyecto interno de Databricks, la empresa fundada por los creadores de Apache Spark, con la intención de resolver un problema común en los equipos de machine learning: la dificultad para gestionar experimentos, reproducir resultados y poner modelos en producción de manera consistente.
En sus inicios, MLflow se presentó como una herramienta ligera que ofrecía tres módulos básicos: Tracking (para registrar métricas y parámetros de los experimentos), Projects (para empaquetar código en entornos reproducibles) y Models (para estandarizar el despliegue de modelos).
Con el tiempo, y gracias a la adopción por parte de la comunidad de código abierto, evolucionó hacia una plataforma más completa, añadiendo funcionalidades como MLflow Registry (un repositorio central para versionar y gestionar modelos) y soporte ampliado para múltiples frameworks y servicios en la nube.
Hoy en día, se ha consolidado como un estándar en el ecosistema de MLOps, integrándose con herramientas modernas de ciencia de datos y escalando tanto en proyectos académicos como en entornos empresariales de gran producción.
Ventajas frente a otros sistemas
En el mundo del machine learning existen muchas herramientas, pero no todas tienen beneficios prácticos que realmente simplifiquen el trabajo diario. Lo importante no son sus funciones, sino las ventajas concretas que obtienen quienes las adoptan en sus proyectos. ¿Quieres saber qué te dará MLflow? ¡Vamos allá!
Mayor eficiencia en la gestión de proyectos
Al usarla, los equipos dejan de perder tiempo valioso en tareas repetitivas o en reconstruir experimentos pasados. La eficiencia se traduce en poder enfocarse en lo realmente importante: mejorar modelos, explorar hipótesis y acelerar la innovación. Frente a sistemas más rígidos, reduce fricciones y evita que la gestión sea un obstáculo para avanzar.
Trabajo colaborativo más fluido
La colaboración es uno de los puntos donde más brilla. Mientras que en otros entornos compartir resultados o versiones de modelos puede convertirse en un dolor de cabeza, aquí se logra de manera clara y organizada. Esto permite que equipos multidisciplinarios trabajen en conjunto sin perder trazabilidad ni duplicar esfuerzos, algo esencial en empresas donde la IA involucra a muchas áreas.
Ahorro en costos y recursos
Usar MLflow significa más orden e implica ahorro. La posibilidad de reutilizar modelos, entornos y configuraciones disminuye la necesidad de empezar desde cero en cada proyecto. Igualmente, su capacidad de integrarse con varios servicios y nubes evita atarse a proveedores específicos, lo que en la práctica reduce costos a mediano y largo plazo.
Menor riesgo en producción
Una de las mayores dificultades del machine learning es llevar un modelo desde el laboratorio hasta la producción sin errores críticos. Aquí radica una ventaja clara: disminuye el riesgo de fallos gracias a la trazabilidad y control en cada etapa.
De ese modo, se asegura que los modelos lleguen a entornos reales con mayor estabilidad, disminuyendo incidentes que, en otros sistemas, pueden resultar costosos y dañinos para la confianza de los usuarios.
Ventaja competitiva sostenible
Más allá de los beneficios inmediatos, lo realmente destacado es cómo proporciona una ventaja competitiva a largo plazo. Las organizaciones que la usan logran una cultura de datos más sólida, con procesos escalables y resultados confiables. Gracias a ello, logran innovar con mayor rapidez y responder mejor a los cambios del mercado, superando a aquellas que dependen de sistemas menos flexibles o fragmentados.
¿Cuál es la diferencia entre Mlops y Mlflow?
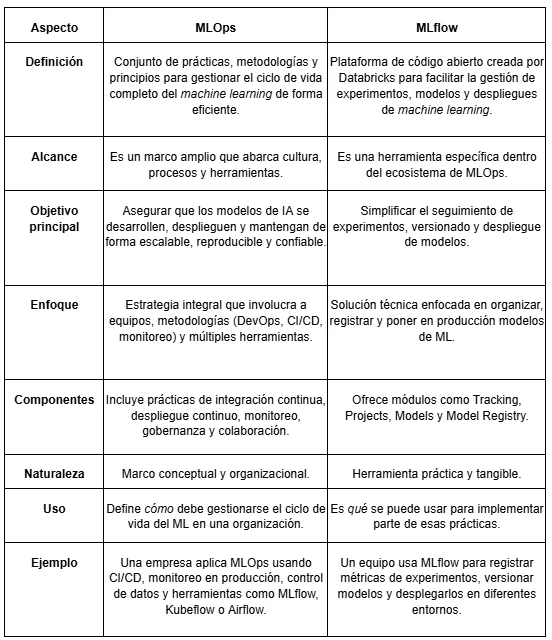
¿Cuáles son los 4 componentes de Mlflow?
MLflow se organiza en cuatro componentes principales, cada uno diseñado para cubrir una parte del ciclo de vida del machine learning. Si no tienes idea de qué hablamos, te lo contamos a continuación:
1. MLflow Tracking
Permite registrar, organizar y visualizar experimentos. Con él se guardan parámetros, métricas, configuraciones y resultados de cada ejecución, para comparar modelos y reproducirlos en el futuro.
2. MLflow Projects
Facilita empaquetar código de machine learning en un formato estándar y reproducible. Gracias a eso, los experimentos pueden ejecutarse de forma consistente en diferentes entornos, sin importar dónde o quién los corra.
3. MLflow Models
Estandariza la forma en que se guardan y despliegan los modelos. Admite múltiples “flavors” (frameworks como TensorFlow, PyTorch, Scikit-learn, entre otros) y facilita llevar un modelo a producción en distintos entornos.
4. MLflow Model Registry
Funciona como un repositorio centralizado para almacenar, versionar y gestionar modelos. Brinda control de versiones, anotaciones, estados (por ejemplo, “en prueba” o “en producción”) y gobernanza del ciclo de vida de cada modelo.
¿Cuáles son las tres etapas admitidas para los modelos en MLflow?
En MLflow, no todos los modelos son iguales ni están listos para producción desde el primer momento. Para gestionarlos de ordenada y seguramente, cada modelo pasa por etapas claras que reflejan su madurez y confiabilidad.
Dichas etapas ayudan a los equipos de machine learning a probar, validar y desplegar modelos sin perder trazabilidad ni control, garantizando que únicamente las versiones confiables lleguen a los entornos reales.
1. Staging (Pruebas)
Es la etapa de validación. Aquí el modelo ya ha sido entrenado y registrado, pero aún se encuentra en fase de pruebas y evaluaciones antes de ser aprobado para un entorno real. Suele usarse para pruebas internas o experimentación controlada.
2. Production (Producción)
El modelo está aprobado y listo para usarse en aplicaciones reales. Esta etapa asegura que la versión elegida es estable y cumple con los requisitos de negocio, precisión y rendimiento.
3. Archived (Archivado)
Se aplica cuando un modelo ya no está en uso o ha sido reemplazado por una versión más reciente. Permite mantener un historial ordenado sin eliminar versiones anteriores, lo que asegura trazabilidad y control.
Guía rápida: Cómo instalar y empezar a utilizarlo
Comenzar con MLflow puede marcar la diferencia entre proyectos de machine learning desorganizados y procesos claros, reproducibles y escalables. Dicho esto, en esta guía rápida te diremos cómo instalarlo, configurarlo y empezar a registrar experimentos y modelos de manera sencilla, incluso si es tu primera vez.
Requisitos previos
- Python (versión 3.7 o superior).
- pip actualizado para instalar paquetes.
- Un entorno virtual recomendado para aislar dependencias.
- Conocimientos básicos de machine learning y Python.
Instalación paso a paso
1. Crea un entorno virtual (opcional pero recomendado):
python -m venv mlflow-env
source mlflow-env/bin/activate # Linux/macOS
mlflow-env\Scripts\activate # Windows
2. Instala MLflow usando pip:
pip install mlflow
3. Verifica la instalación ejecutando:
mlflow --version
Configuración inicial
- Inicia el servidor de seguimiento para registrar experimentos: mlflow ui
- Esto abrirá la interfaz web en http://127.0.0.1:5000.
- Puedes empezar a registrar experimentos y métricas usando código Python:
import mlflow
mlflow.start_run()
mlflow.log_param("alpha", 0.5)
mlflow.log_metric("accuracy", 0.87)
mlflow.end_run()
Recomendaciones y buenas prácticas
- Siempre trabaja con entornos virtuales para evitar conflictos de dependencias.
- Registra todos los experimentos, incluso los que fallan, para mantener trazabilidad.
- Usa nombres claros y consistentes para los experimentos y modelos.
- Mantén tu Model Registry organizado y versiona cada cambio significativo.
- Integra MLflow con sistemas de CI/CD si planeas desplegar modelos en producción.
Ejemplos y casos de uso
Por si no te ha quedado claro, hemos estado hablando de una herramienta que no sirve nada más para el registro de experimentos: su versatilidad deja aplicarlo en distintos escenarios reales, desde la investigación hasta la producción empresarial. ¿Quieres conocer algunos casos de uso? ¡Sigue leyendo!
Seguimiento y comparación de experimentos
Equipos de científicos de datos lo emplean para llevar un registro detallado de cada prueba realizada sobre un modelo. Esto permite comparar versiones, evaluar métricas y parámetros, y decidir cuál es la mejor estrategia sin perder información, evitando errores y repeticiones innecesarias.
Gestión de modelos en producción
En entornos empresariales, se emplea para organizar y controlar modelos listos para desplegar. Su sistema de versionado y registro promueve el llevar modelos de laboratorio a producción de manera segura, asegurando que solo las versiones validadas estén disponibles para uso real.
Integración con pipelines de automatización
MLflow se incorpora dentro de flujos de trabajo automatizados para entrenar, evaluar y desplegar modelos continuamente. Debido a eso, el ciclo de vida de un modelo se gestione de forma eficiente, acelerando la entrega de resultados y reduciendo riesgos asociados a errores humanos.
Educación e investigación en IA
Instituciones académicas y laboratorios lo usan para documentar experimentos, compartir resultados y reproducir estudios. Simplifica la colaboración entre estudiantes e investigadores, promoviendo transparencia y consistencia en los proyectos de aprendizaje automático.
Limitaciones y riesgos de su uso
Incluso las herramientas más potentes tienen sus retos, y MLflow no es la excepción. A medida que los proyectos de machine learning crecen en complejidad, algunas dificultades aparecen: desde la gestión de grandes volúmenes de modelos hasta la necesidad de disciplina en el registro de experimentos. Conocer esas áreas críticas no busca desanimar, sino preparar a los equipos para sacar el máximo provecho sin sorpresas desagradables.
Curva de aprendizaje inicial
A pesar de que su instalación es sencilla, aprovechar todas sus funcionalidades puede ser complejo para quienes no están familiarizados con machine learning o MLOps. Configurar experimentos, modelos y registros correctamente requiere tiempo y práctica.
Escalabilidad en entornos muy grandes
En proyectos con cientos de modelos o múltiples equipos simultáneos, MLflow puede requerir ajustes avanzados en infraestructura, bases de datos y almacenamiento para mantener un rendimiento óptimo. Sin estos ajustes, el sistema puede volverse lento o difícil de gestionar.
Dependencia de buenas prácticas del usuario
La efectividad del sistema depende en gran medida de cómo los equipos registren experimentos, nombren modelos y gestionen versiones. Sin disciplina y estándares claros, se puede generar desorganización, pérdida de trazabilidad o errores en producción.
¿Existen alternativas a MLflow?
- Kubeflow: sistema open source orientada a la ejecución de pipelines de machine learning en Kubernetes. Permite entrenar, desplegar y escalar modelos de forma automatizada, ideal para entornos con infraestructura en la nube y flujos de trabajo complejos.
- Weights & Biases (W&B): se centra en el seguimiento de experimentos y colaboración entre equipos. Tiene dashboards interactivos, comparación de modelos y visualización de métricas en tiempo real, con integración sencilla con frameworks populares como TensorFlow o PyTorch.
- Neptune.ai: especializado en la gestión de experimentos y la trazabilidad de modelos. Permite registrar parámetros, métricas y artefactos de manera estructurada para la colaboración entre equipos y la reproducibilidad de resultados.
- TensorBoard: herramienta de visualización de TensorFlow que ayuda a monitorizar y depurar experimentos. Aunque es más limitada en cuanto a gestión de modelos, es muy útil para análisis de métricas y visualización de entrenamientos.
- Comet.ml: provee seguimiento de experimentos, comparación de modelos y gestión de datos. Permite colaborar en tiempo real y proporciona integraciones con múltiples frameworks de machine learning, facilitando la organización de proyectos complejos.
Te puede interesar: IA para programar online gratis.
Preguntas frecuentes (FAQs)
MLflow se considera una de las herramientas más populares para gestionar proyectos de machine learning, pero es natural que surjan dudas antes de adoptarla. A continuación, respondemos las preguntas más comunes para aclarar su uso, ventajas y cómo se compara con otras soluciones en el ecosistema de inteligencia artificial.
¿MLflow tiene una interfaz de usuario?
Sí, incluye una interfaz web llamada MLflow UI para visualizar experimentos, métricas y modelos de manera intuitiva. Facilita comparar resultados, revisar parámetros y gestionar el ciclo de vida de los modelos sin necesidad de usar solo la línea de comandos.
¿El uso de MLflow es gratuito?
Sí, es open source y se puede usar de manera gratuita. Sin embargo, algunas implementaciones en la nube o integraciones avanzadas con servicios de terceros pueden tener costos asociados.
¿Cuál es mejor, MLflow o Kubeflow?
No hay un “mejor absoluto”. MLflow es ideal para registro de experimentos, seguimiento y gestión de modelos, mientras que Kubeflow es más completo para pipelines de ML en Kubernetes y despliegues a gran escala. La elección depende del tamaño del proyecto y la infraestructura disponible.
¿Cuál es la diferencia entre LangChain y MLflow?
LangChain se centra en aplicaciones de inteligencia artificial basadas en modelos de lenguaje, como chatbots o agentes autónomos. MLflow, en cambio, es una plataforma de gestión del ciclo de vida de modelos en general, para cualquier tipo de machine learning.
¿Vale la pena aprender MLflow?
Sí, sobre todo si trabajas en proyectos de machine learning que requieren organización, reproducibilidad y despliegue confiable de modelos. Aprenderlo simplifica la colaboración, reduce errores y mejora la eficiencia, convirtiéndose en una habilidad muy valorada en equipos de datos modernos.
Lleva tus proyectos de machine learning al siguiente nivel con EBIS
MLflow es una plataforma diseñada para gestionar con éxito proyectos de machine learning. Desde el seguimiento de experimentos, hasta el despliegue de modelos en producción, MLflow permite que los profesionales de data science trabajen de manera organizada y eficiente.
En EBIS Business Techschool sabemos lo importante que es dominar este tipo de herramientas. Por eso hemos creado el Máster en Máster en Data Science e Inteligencia Artificial un programa integral que combina teoría, práctica y proyectos aplicados para que aprendas a gestionar, versionar modelos y llevar tus desarrollos de machine learning a entornos reales.
Con EBIS accederás a formación online flexible, tutorías con expertos en ciencia de datos. Además, podrás obtener una doble titulación junto a la Universidad de Vitoria-Gasteiz, potenciando tu perfil profesional. ¡Convierte tus proyectos de machine learning en soluciones efectivas con EBIS!
Conclusión
MLflow no debe entenderse únicamente como una herramienta técnica. Representa una filosofía que coloca la transparencia, la reproducibilidad y la escalabilidad en el corazón de cada proyecto de machine learning. En un contexto donde las organizaciones buscan extraer valor real de sus datos, contar con un sistema confiable para gestionar experimentos y modelos se convierte en un requisito imprescindible.
Actualmente, es un sistema que no solo ordena procesos, sino que impulsa a los equipos a trabajar con visión estratégica. Adoptarlo es abrazar un estándar que marcará la diferencia en el competitivo mundo de la inteligencia artificial moderna. ¿Listo para entrar en la nueva tendencia?
Compártelo en tus redes sociales
Másteres destacados






Centro inscrito en el Registro Estatal de Entidades de Formación en virtud de la ley 30/2015
EBIS Enterprise SL, B75630632; C. Agustín Millares, 18, 35001 Las Palmas de Gran Canaria; © 2025 EBIS Business Techschool,